
Pandas Part 2. DataFrame
카테고리: Basic
DataFrame
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,
}
gdp = pd.Series(gdp_dict)
country = pd.DataFrame({
'population': population,
'gdp': gdp
})
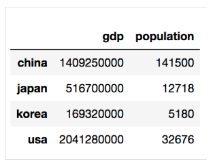
딕셔너리로 변환할 수 있음
country.index
# Index(['china', 'japan', 'korea', 'usa'], dtype='object')
country.columns
# Index(['gdp', 'population'], dtype='object')
country['gdp']
type(country['gdp'])
# pandas.core.series.Series
Series도 numpy array처럼 연산자를 활용
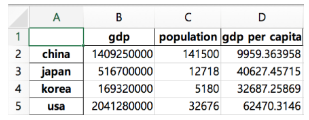
gdp_per_capita = country['gdp'] / country['population']
count['gdp per capita'] = gdp_per_capita

데이터 프레임을 저장
country.to_csv("./country.csv")
country.to_excel("country.xlsx")
country = pd.read_csv("./country.csv")
country = pd.read_excel("country.xlsx")
💡 Indexing / Slicing
.loc: 명시적인 인덱스를 참조하는 인덱싱/ 슬라이싱
country.loc['china']
country.loc['japan':'korea', :'population']

.iloc: 파이썬 스타일 정수 인덱스 인덱싱/ 슬라이싱
country.iloc[0]
country.iloc[1:3, :2]
DataFrame 새 데이터 추가/ 수정
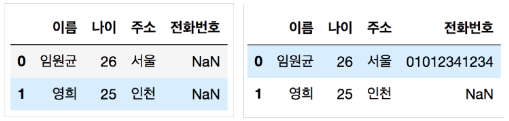
dataframe = pd.DataFrame(columns=['이름', '나이', '주소'])
dataframe.loc[0] = ['임원군', '26', '서울']
dataframe.loc[1] = {"이름": '철수', '나이': '25', '주소': '인천'}
dataframe.loc[1, '이름'] = '영희'

DataFrame 새 컬럼 추가
dataframe['전화번호'] = np.nan
dataframe.loc[0, '전화번호'] = '01012341234'
len(dataframe)
컬럼 선택하기
- 컬럼 이름이 하나만 있다면 Series
- 리스트로 들어가 있다면 DataFrame
dataframe["이름"] dataframe[['이름', '주소', '나이']]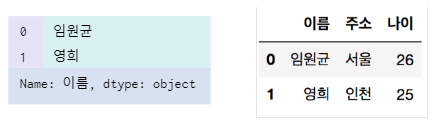
댓글 남기기