
Pandas Part 3. 연산과 함수
카테고리: Basic
누락된 데이터 체크
- 튜토리얼의 데이터와 다르게 현실 데이터는 일부 누락되어 있응 형태가 많음
dataframe.isnull() dataframe.notnull()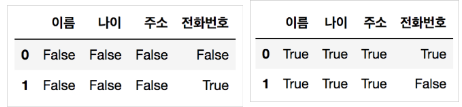
dataframe.dropna()
dataframe['전화번호'] = dataframe['전화번호'].fillna('전화번호 없음')

Series 연산
- numpy array에서 사용했던 Series연산자들을 동일하게 활용할 수 있음
A = pd.Series([2, 4, 6], index=[0, 1, 2]) B = pd.Series([1, 3, 5], index=[1, 2, 3]) A + B A.add(B, fill_value=0) # B에 없는 A의 데이터는 0으로 처리해서 덧셈해라
DataFrame 연산
- add(+), sub(-), mul(*), div(/)
A = pd.DataFrame(np.random.randint(0, 10, (2, 2)), columns=list("AB")) B = pd.DataFrame(np.random.randint(0, 10, (3, 3)), columns=list("BAC")) A + B A.add(B, fill_value=0)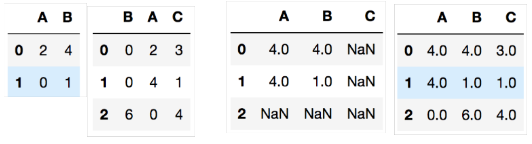
집계함수
- numpy array에서 사용했던 sum, mean 등의 집계함수를 동일하게 사용할 수 있음
data = { 'A' : [i+5 for i in range(3)], 'B' : [i**2 for i in range(3)] } df = pd.DataFrame(data) df['A'].sum() # 18 df.sum() df.mean()
값으로 정렬하기
sort_values()
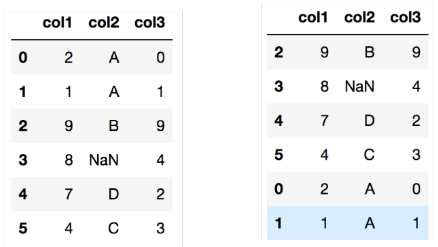
df= pd.DataFrame({
'col1': [2, 1, 9, 8, 7, 4],
'col2': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3': [0, 1, 9, 4, 2, 3],
})
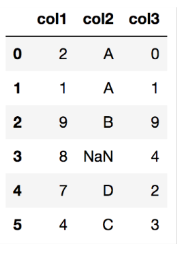
df.sort_valuee('col1')
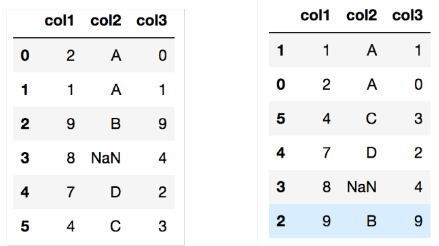
df.sort_values('col1', ascending=False)
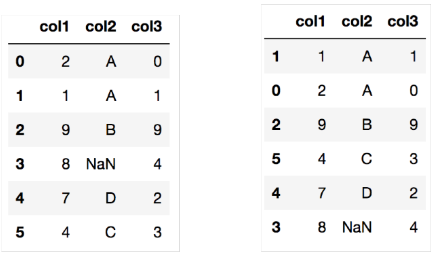
df.sort_values(['col2', 'col1'])
댓글 남기기