
머신러닝 개론
카테고리: ML
태그: 기초
인공지능이란
- “기계가 경험을 통해 학습하고 새로운 입력 내용에 따라 기존 지식을 조정하며 사람과 같은 방식으로 과제를 수행할 수 있도록 지원하는 기술”
- 인공지능은 머신러닝 기법 외에도 데이터를 통해 패턴을 학습하는 방법들을 포괄
- 딥러닝은 머신러닝 기법 중 인공신경망 모형을 사용하는 특별한 예시
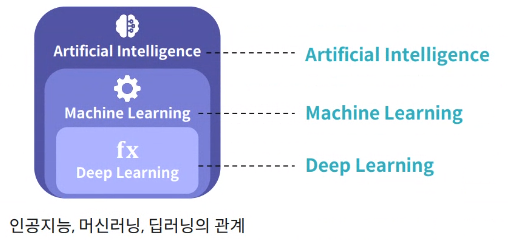
인공지능의 구분
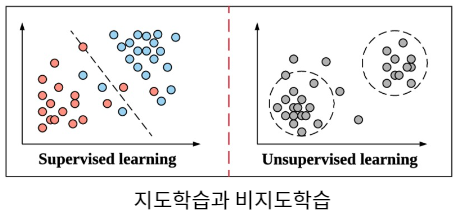
지도학습(Supervised Learning)
정답(레이블)이 존재하는 상태에서 학습
ex) 회귀 분석, 분류 분석
- 목표 : 입력값(input)과 출력값(output) 사이의 함수 관계(mapping)를 학습
- 예시 : 선형회귀모형, 서포트 벡터 머신, 의사결정나무, 최근접 이웃
- 장점 : 해결해햐 할 문제의 정의가 명확하며 학습 방법이 비교적 직관적
- 단점 : 정답(레이블)이 달려있는 대량의 데이터셋 필요
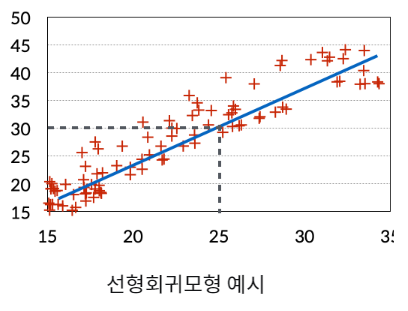
회귀문제 (Regression)
입력 데이터(input Feature)를 바탕으로 연속적인 출력(Continuous Output) 예측
ex) 서울시 집값 예측(가격), 기대 수명 예측(나이)
간단한 선형회귀 모형부터 복합적인 비선형 모형까지 상황에 맞게 사용
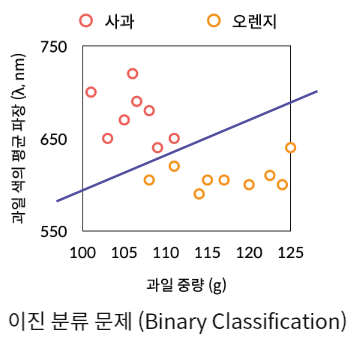
분류 문제 (Classification)
입력 데이터(input Feature)를 바탕으로 이산적인 출력(Categorical Output) 예측
ex) 타이타닉 생존 예측(생존/사망), 사기 탐지(진실/거짓)
주로 서포트 벡터 머신 분류기와 의사결정나무 기반 모형이 널리 활용됨
비지도학습(Unsupervised Learning)
정답(레이블)이 존재하지 않는 상태에서 학습
ex) 군집 분석, 차원 축소
- 목표 : 정답(레이블)이 별도로 존재하지 않는 상황에서 데이터의 구조 학습
- 예시 : K-Means 군집화, PCA, t-SNE
- 학습에 별도의 레이블이 필요 없으며, 학습 설계에 따라 높은 잠재력을 지님
- 지도학습에 비해 학습 자체가 쉽지 않고, 평가 기준도 모호한 편
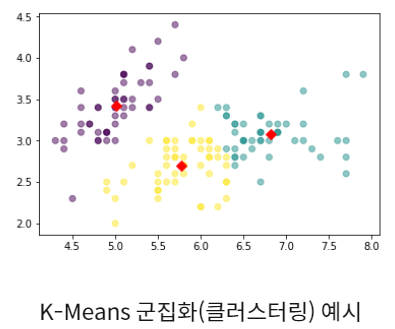
군집 분석 (Clustering)
데이터 관측값들 간 유사도를 기준으로 사전에 정의된 개수의 군집으로 분할
ex) 쇼핑 패턴을 바탕으로 한 고객 군집화
K-Means 군집화 모형이 대표적이며, 계층적 군집화도 사용됨
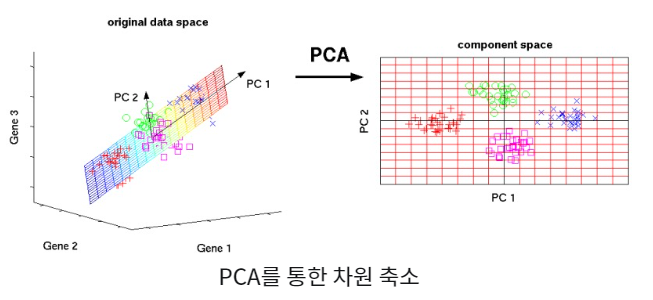
차원 축소 (Demension Reduction)
고차원 데이터의 핵심 축을 기반으로 정보 손실을 줄이며 낮은 차원으로 변환
ex) PCA, t-SNE 알고리즘을 활용한 데이터 시각화
고차원의 데이터는 눈으로 분포를 확인하는 것이 어렵기 때문에 차원 축소 후 시각화하는 경우가 많음
경험적 위험 최소화와 일반화
머신러닝 기본 용어
- 학습 데이터: 모형 훈련을 위한 데이터. 입력 데이터와 정답(레이블)이 함계 존재하여 모형 적합에 활용
- 시험 데이터: 모형 평가를 위한 데이터. 입력 데이터만 존재하는 상황을 가정하며, 학습에서는 배제
- 모형: 특정 업무(task)를 수행하기 위한 학습 가능한 알고리즘
- 학습: 주어진 학습 데이터에서의 오차를 최소화하는 방향으로 모형을 적합(fitting)하는 과정
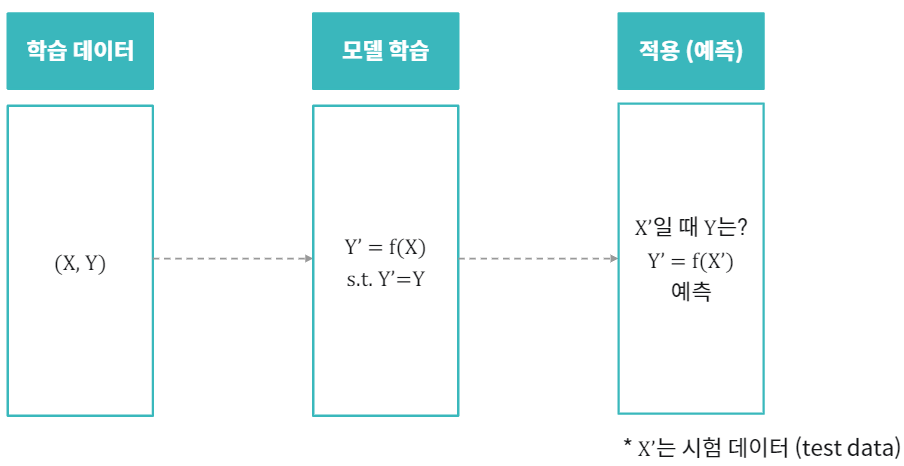
머신러닝 시나리오 (지도학습)
머신러닝 기본 가정

훈련 데이터가 무작위 샘플링이 아니라면?
우리에게 주어진 데이터 샘플(data point)이 모집단의 분포를 대변한다고 볼 수 없음
ex) 한국인의 기대 수명을 예측하는데, 관측치가 전부 50대 남성 흡연자의 샘플이라면?
-> 한국의 기대 수명에 대한 예측을 실시할 수 없음시험 데이터에 정답이 존재한다면?
예측 모델을 학습할 필요가 없음
머신러닝 문제의 핵심은 결과를 모르는 상황에 대한 예측훈련 데이터와 실험 데이터의 분포가 다르다면?
훈련 데이터에 학습시킨 모델이 시험 데이터에서 좋은 성능을 낼 것이라 기대할 수 없음
ex) 훈련 데이터: 2000년대 한국인의 기대 수명 데이터
시험 데이터: 1400년대 유럽인의 기대 수명 예측
위와 같은 경우 훈련 데이터에서 모델이 학습한 패턴이 시험 데이터로 일반화될 것이라 기대하기 어려움경험적 위험 최소화 (ERM: Empirical Risk Minimization)
우리에게 주어진 데이터는 훈련데이터 (Training data)
머신러닝의 3가지 기본 가정 하에서, 우리는 훈련 데이터 셋에 대해 모델을 학습
일반적으로, 훈련 데이터에서의 예측 성능 향상은 시험 데이터에서의 성능 향상으로 이어짐(기본 가정 만족 시)
일반화 (Generalization)
머신러닝 모델을 학습시키는 진짜 이유는 새로운 데이터(시험 데이터)에서의 예측력을 높이는 것
즉, 대부분의 경우 훈련 데이터에서의 성능보다는 일반화 성능이 중요
머신러닝의 기본 가정이 모두 만족도리 경우, 머신러닝 모형은 어느 정도의 일반화 성능을 기대할 수 있음
과대적합과 과소적합
모형의 복잡도
주어진 모형이 얼마나 복잡한 데이터 패턴을 학습할 수 있는지를 나타내는 정도

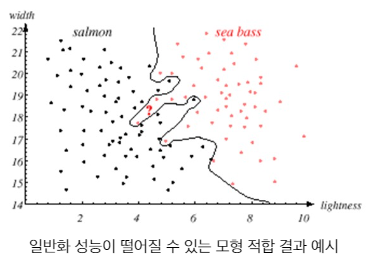
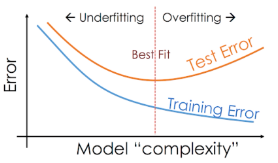
과대적합 (Overfitting)
모형의 복잡도가 데이터셋에 비해 높아서, 훈련 데이터의 핵심 패턴 뿐아니라 노이즈까지 학습한 상태
훈련 데이터에서의 성능은 높으나, 새로운 데이터에 대한 일반화 성능이 떨어지게 됨
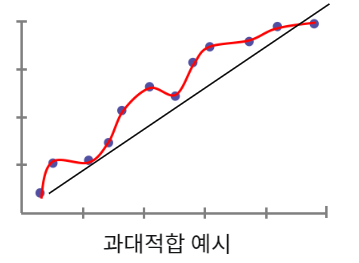
과소적합 (Underfitting)
모형의 복잡도가 데이터셋에 비해 낮아서, 훈련 데이터의 핵심 패턴을 충분히 학습하지 못한 상태
모형이 데이터의 패턴을 학습하지 못하여, 훈려 데이터와 시험 데이터 모두에서 낮은 성능을 보임
🔥머신러닝 모형 선택
데이터의 복잡도를 고려한 적절한 크기의 모형을 선택하는 것이 중요
과대적합과 과소적합 사이의 이상적인 지점을 추구
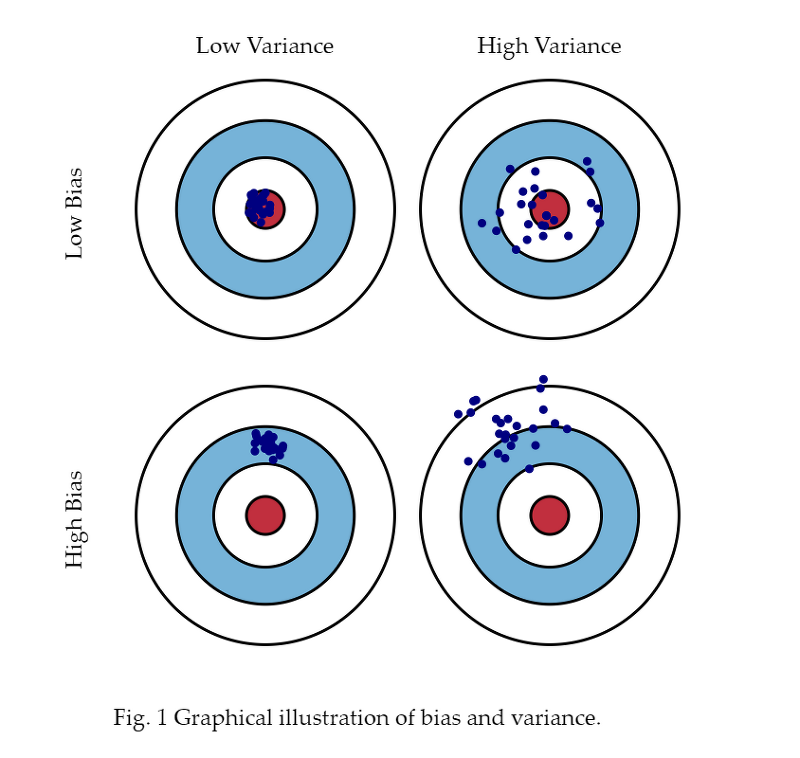
Bias-Variance Trade-off
Bias(편향): 모형이 잘못된 가정을 했을 때의 오차Variance(분산): 학습데이터의 변동에 따른 오차
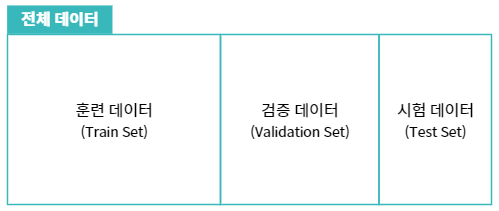
데이터셋의 분할과 교차 검증
기본적으로 머신러닝 데이터는 모형 학습에 사용되는 훈련 데이터와 모형 평가에 사용되는 시험 데이터로 구분

검증 데이터의 필요성
훈련 데이터로 학습을 진행하면 훈련 데이터에 대한 예측 오차는 보통 계속 감소
또한, 모형의 크기가 커질수록 훈련 데이터에 대한 오차는 감소하는 경향(과대적합)
과대적합 문제가 발생할 경우 새로운 데이터에 대한 일반화 성능 약화
과대적합을 탐지하고 완화하기 위해 시험 데이터를 모방하는 검증 데이터 구비
검증 데이터란?
훈련 데이터셋의 일부를 모형 학습에 사용하지 않고, 학습 중 모형 평가에 활용
즉, 훈련 데이터에서 학습된 모형의 일반화 성능을 검증 데이터를 통해 평가
검증 데이터의 활용: 하이퍼파라미터 (Hyperparameter)
데이터 외부적으로 결정되는 모형의 형태와 관련된 변수
ex) K-최근접 이웃 알고리즘의 K값 / 다항 회귀 모형의 차수
이들은 모형의 구조, 복잡도 등을 결정하므로 보통 학습을 시작하기 전에 교차 검증을 통해 결정
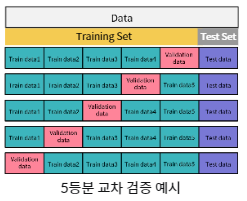
교차 검증
K-Fold 교차 검증 (Cross-Validation)
전체 훈련 데이터를 K-등분 한 후 각 분할(partition)을 검증 데이터로 하여 총 K번 학습/평가를 진행
K번 학습 결과를 종합하여 검증 데이터에서 가장 높은 성능을 보인 하이퍼 파라미터를 채택
데이터 분석
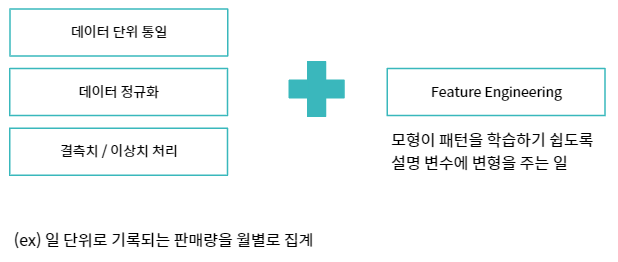
데이터 전처리
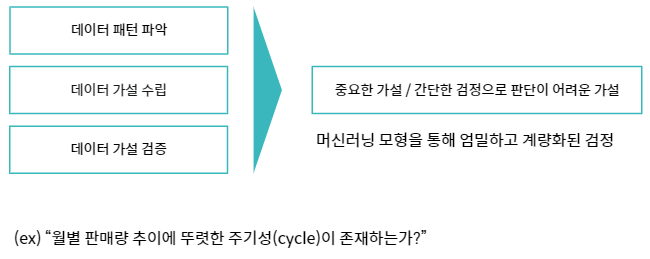
탐사적 자료 분석 (EDA)
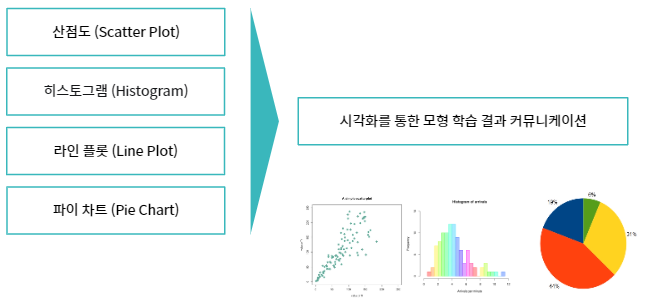
데이터 시각화
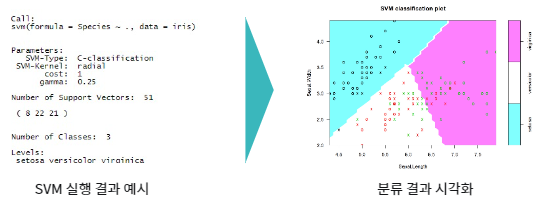
모형 학습 결과 의사소통
댓글 남기기